AAC生成AIナレッジシステムPoCの開始
会社の方針はトップダウンで決まる場合とボトムアップで進む場合があります。
トップダウンの場合、良き理解者(出来れば業務・IT・プロジェクトがわかる方)がいて、社
内の状況も見渡してリーダシップを取って進めるやり方です。
ボトムアップの場合、利用者側が声を上げる場合とIT部門が声を上げる場合があります
が、IT化検討時には両方の参画が必要です。
ここでは、どのパターンで始めるとしても、失敗を出来るだけ回避する為に、スモールスタ
ートは無論ですが、スモールスタートの具体的な作業についても述べたいと思います。
目的としてはPoC(実証実験、Proof of Concept)です。(弊社では下図一連を実施済)
また、弊社では製造業においては下図全ての工程においてご支援可能です。
製造業以外においても大半はご支援可能です。
ご依頼がございましたら、ファシリテータも可能です。
もし、学習データ取得先である”XXデータ管理システム”が出来ていない場合は、そちらの
ご支援も可能です。
2023年10月5日
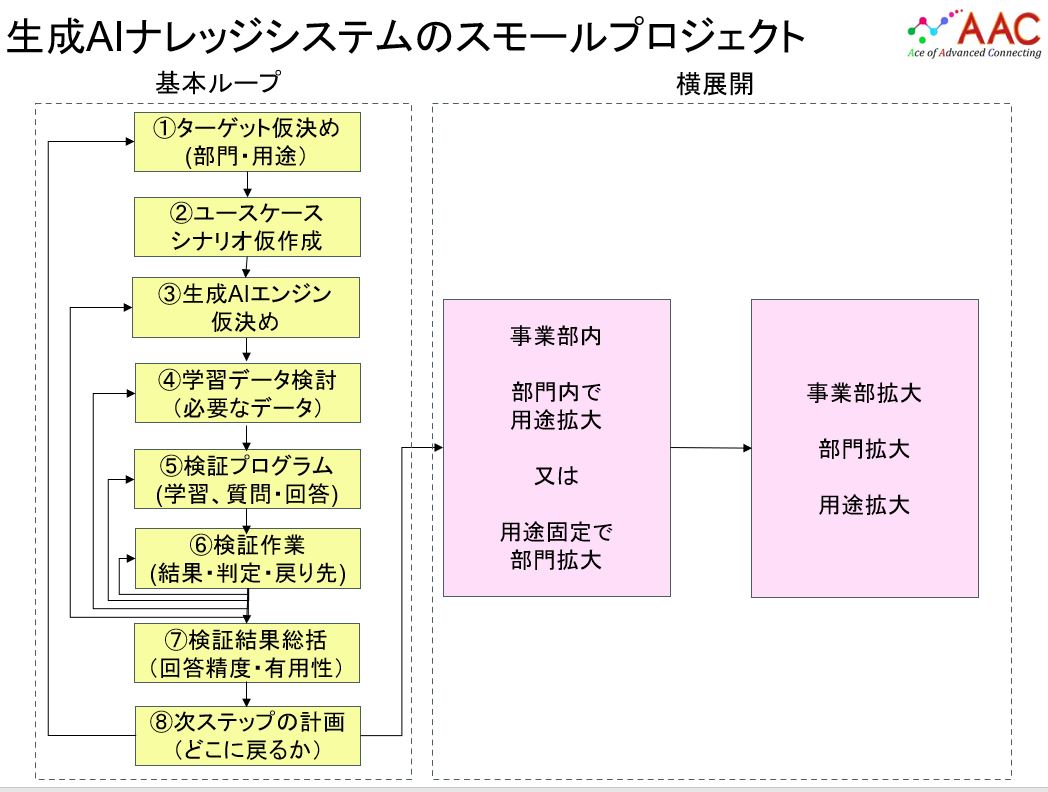
スモールプロジェクトの工程手順説明(番号は上図基本ループの番号に対応しています)
1 ターゲットの絞込み(お客様及び弊社)
2 利用シーンのシナリオ作成(お客様及び弊社、質問・期待する回答含む)
3 生成AIエンジンの想定(お客様及び弊社)
4 学習データの検討(お客様及び弊社)
5 検証プログラムの準備(お客様又は弊社)
6 検証作業、検証結果記録(お客様及び弊社、上記2の質問・回答・判定等の記入)
7 検証結果総括(お客様及び弊社、回答精度の集計・期待する回答の有用性等)
8 次ステップの計画(お客様、上記7の結果で途中に戻るのか、利用範囲)
などになります。
以下に、各々の工程についてご説明させて戴きます。
1 ターゲットの絞込み
これまで”生成AI特集”で述べたユースケースや”用途別活用特集”で述べた用途別
利用シーン、利用方法等も参考にして、社内で比較的課題の多い用途(設計仕様変
更、生産技術事前確認、品質問題対応、・・・)に絞る方法もあります。
この工程は事業部門のマネージャークラスから課題感を伺ったり、担当者クラスから
課題解決のボトルネックになっている問題で声を上げて戴くのが良いと思います。
2 利用シーンのシナリオ作成
ターゲットが決まったら、
解決したい課題、その為の質問、期待する回答を得る為の学習データ等のシナリオを作成します。
例えば、品証部門の個別の品質問題対応の時、
過去の同一品番の品質問題
過去の同一品名の品質問題
指定期間の同一品番の品質問題
を質問したいとします。
期待する回答としては、過去の同一品番、同一品名の品質問題情報全てや指定期
間内に発生した品質問題情報全てになると思われます。
また、当時の詳細確認をする為に、対応者及び関係者、発生及び対応日、詳細内容
を確認する為に、報告書の場所(パスとファイル名等)も知りたいとします。
すると、学習データとしては、それらの情報全てを含んでいないといけないことにな
り、既存の”XXデータ管理システム”のDBに入っている必要があります。
これらが”XXデータ管理システム”のDB項目に入っていれば良いのですが、もし入っ
ていない項目があった場合は、項目の追加、追加項目へのデータの追加等が必要に
なります。
このようにして、質問・回答・学習のセットで整合性を調整します。
3 生成AIエンジンの想定
生成AIエンジンを選定します。
弊社では、先ずはChatGPTの開発会社であるOpenAI社のGPTモデルとAPIでやりま
した。
どこまでやるかの問題もありますが、生成AIエンジンを選定する時、本システムを実
現する為に、幾つかの前提条件がございます。
弊社特集頁の生成AI特集の”7 生成AIエンジンの選び方”に、それら前提条件を含
む生成AIエンジンの選び方の参考情報もございますので、参考にして戴ければと思
います。
特に、生成AIエンジンは多くの製品が発表されたり出荷されたりしており、選ぶ側にも
基準が必要になりますが、弊社生成AIナレッジシステムの実現には欠かせない条件
もございます。
4 学習データの検討
前記シナリオを基に、学習データの内容やデータの取得先を整理します。
質問と回答に関係する学習データを”XXデータ管理システム”から取得したり、登録さ
れてないファイルを登録したり、記録されていない情報を文書化して登録したりという
作業になると思います。
5 検証プログラムの準備
学習、質問&回答の一連の作業を実現する為の検証プログラムを準備します。
弊社では一連を実施済なので、参考にして戴くことも可能です。
検証プログラムは学習側と質問・回答側に分けてある方が望ましいです。
また、学習側はバッチ形式でファイル単位で学習出来る方が望ましいです。
弊社の検証プログラムはそのようになっているので、導入初期段階でバッチ形式で学
習させたり、追加で学習させたりも可能です。
新しく発生した学習させたいデータについても、日常業務のシステムに組み込んで運
用し、常に最新社内情報も学習、質問出来る仕組もあった方が良いです。
僅かな処理時間以外は、出来るだけ利用者に意識させないやり方が望ましいと思わ
れます。
6 検証作業、検証結果記録
一連の基本ループの中で、判断が必要な工程です。
質問に対する回答を判定します。
それによって、基本ループ内のどこに戻るのかを判断します。
例えば、
質問の仕方に問題があった場合は質問を変えて再度質問します。
プログラムに問題がありそうであれば、プログラムを見直しします。
学習データに問題があると考えられる場合は学習データを見直しします。
用途に向き・不向きがある可能性もゼロではないので、用途も見直します。
等です。
弊社では架空の製造業の学習データを作成して行っていますが、質問の仕方とプロ
グラムの見直しを繰返して、見通しを立てました。
架空の製造業ではありますが、自動車事業部(量産品)の仕組を航空事業部(一品
物)への横展開も想定した検証も一部行いました。
7 検証結果総括
一連の検証結果を集計して回答精度を算出します。
俯瞰的に見て、全体的に問題ないのか、部分的に問題があるのか等を判断します。
前記”検証作業”を繰返し、それらの検証結果を踏まえて、当初立てた”ターゲット”で
の運用の見通しが立ったのか、立たなかったのかを総括します。
これらがPoCの結果報告書となり、今後の計画に反映させることになります。
8 次ステップの計画
前記検証結果や総括を基に、次ステップの方針を決めたり、計画の見直しをしたりし
ます。
もし、結果的に回答精度に問題なく、横展開(用途、部門、事業部等の拡大)が可能
であれば、社内調整を行いながら、次のステップに進みます。
個別打合せにおいてご説明させて戴いたお客様には”概説書”(HPでは非公開)をご
案内させて戴いていますが、概説書内の”ロードマップ”も参考にして戴けますと、より
現実味が出て来ると思います。
以上です。
ご不明な点は弊社までお問合せ下さいますよう、お願い申し上げます。